クローリングとは?仕組みとクローラーの促進&抑制方法|検索エンジンの仕組みを理解しよう

SEOにおいて、クローラーが行うクローリングはほとんど意識されないポイントです。
しかしクローリングは、Webページが検索結果に表示される最初の工程です。
クローリングが正しく行われなければ、そもそも検索結果に表示されず、順位どころではありません。
ここをクリアしないかぎり、すべてが始まらないのです。
このように、死活的に重要な技術要素であるクローリングについて、まずは基礎的な知識を学んでいきましょう。その上で、やや高度な検索エンジンの制御方法についても解説していきます。
一見難しいようですが、この記事の内容を理解することで、検索エンジンにやさしい造りのWebサイトを作ることができます。
また、「SEOの要件と、ユーザーの利便性やデザインが相反する」などの判断の難しいケースにおいて、適切な方法を見出すための手がかりとなるでしょう。
目次
1.検索エンジンの仕組みの概要
1-1.検索から表示までの流れ
1-2.クローリングとは
2.クローラーの基本動作
2-1.Webページの巡回
2-2.クローリングするファイルの種類
2-3.パーシング(解析)
3.クローラーの種類
3-1.Googlebot|Googleのクローラー
3-2.その他のクローラー
4.クローリングの確認
4-1.クローリングの頻度
4-2.クローリングを確認する方法
5.クローラーの制御
5-1.クローリングを開始させる
5-2.クローリングを促進する
5-3.クローリングを抑制する
6.クローラビリティを高める
6-1.リンクのないページを排除する
6-2.リンクの数を適正に抑える
6-3.トップページからの必要クリック数を抑える
6-4.トップページから主要ページへ直接リンクする
6-5.ページ送りを少なくする
6-6.Javascriptでのリンクを避ける
6-7.複雑なURLを避ける
7.最後に|クロールバジェットを気にする必要はない
1.検索エンジンの仕組みの概要
わたしたちは気軽に「検索エンジン」という言葉を使いますが、それがなんなのかうまく説明できない人も多いでしょう。
まずは検索エンジン全体の仕組みを把握し、その中でクローリングがどのような働きをしているのかを理解していきましょう。
1-1.検索から表示までの流れ
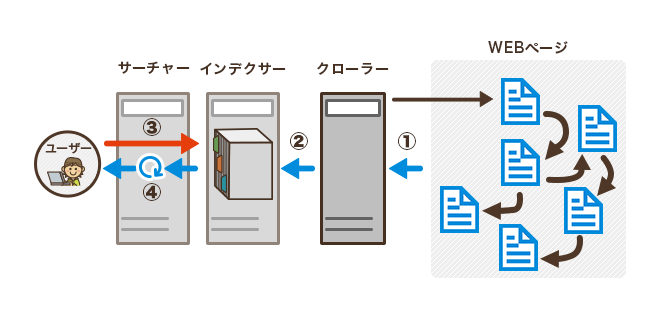
「検索エンジン」といわれると、Googleなどの巨大なシステムを連想する人が多いでしょう。しかし、社内の数人だけが使うような、ごく小規模な検索エンジンもあります。
このような規模の大小にかかわらず、検索エンジンの基本的な構成は、それほど大きくは変わりません。
検索エンジンは、主に3つの機能に分類できます。
a.クローラー
Webページを次々に巡回して、記載されている情報を取得する
b.インデクサー
クローラーが取得した情報を記憶する
c.サーチャー
格納された情報からキーワードに関する情報だけを抽出し、重要度に応じて並べ替える
検索エンジンは、検索ボタンをクリックした瞬間に、広大なインターネット空間から情報を探してくるわけではありません。
あらかじめ情報を収集しておき、Google社が保有しているサーバーの内部に記憶しておくのです。
Google自体が情報を保有しているから、瞬時に必要な情報を表示できるわけです。
「サーバー」といわれてピンとこない人もいると思いますが、基本的にはパソコンと同じコンピューターです。
質的な機能はさほど変わりません。
コンピューターの前に座っている人が使うのがパソコンで、ネットワークにつながっていてなにかの機能を提供するために共有されているのがサーバーです。
検索エンジンの機能である「クローラー」「インデクサー」「サーチャー」の3つは、それぞれがサーバーです。
これらの仕組みは、「検索エンジンの仕組みの理解がSEOを正しく理解する近道だ」で詳しく解説してあります。
1-2.クローリングとは
クローラーというサーバーの中には、インターネットを巡回するプログラムが動作しています。
WebサイトやWebページ巡回して情報を収集し、インデクサーに引き渡すという処理をしています。
クローラーが行うこの処理を「クローリング」といいます。
クローリングは、検索エンジンが行うすべての処理の起点です。
つまり、クローリングが行われなければ、検索結果に表示されることはないのです。
2.クローラーの基本動作
人間はWebの画面上にあるリンクをクリックすることで、あるページから別のページの情報を見に行きます。
クローラーの動作も人間がリンクをたどる動きと似ていますが、リンクの見つけ方が人間とは違います。
人間がリンクを視覚的に発見するのに対して、クローラーはHTMLを読み込んでリンクを発見します。
すこしわかりづらいですね。例を挙げて解説していきましょう。
まずは下の文章を見てみてください。
タラバガニ
甲殻類の一種である。タラバガニ属はタラバガニを含む5種からなる。和名に「カニ」の名があるが、生物学上はヤドカリの仲間である。
人間はこの画面を見ると、「タラバガニ」の箇所がクリックできると認識します。
それはWebブラウザによって、文字の色が他の部分と変えられたり、下線が引かれたりするためですね。
クローラーは、人間のように見た目でリンクを判断するのではなく、HTMLを読んでリンクを判断します。
上の「タラバガニ」の説明を、クローラーから見えている形に変えてみましょう。
<a href=”https://ja.wikipedia.org/wiki/タラバガニ”>タラバガニ</a><br />
甲殻類の一種である。タラバガニ属はタラバガニを含む5種からなる。和名に「カニ」の名があるが、生物学上はヤドカリの仲間である。
Webページは、本来このようにHTMLで記述されています。
そしてクローラーはHTMLを読んでいます。
上の例でいうと、クローラーはリンクタブで挟まれた「タラバガニ」という部分を別のページへのリンクだと認識して、そのリンクをたどり情報を収集します。
2-1.Webページの巡回
このように、クローラーはHTMLの中にあるリンクを発見してはたどっていくことで、次々とWebページを巡回して情報を取得していきます。
リンクによってWebページ同士はつながれており、このリンクのつながり方は昔からクモの糸に例えられています。そもそもわたしたちが「Web」とよんでいるシステムは、世界中に広がる情報網がクモの巣のように見えることから、「World Wide Web(世界中に広がるクモの巣)」と名付けられています。
クローラーは、糸の上を自由に渡り歩くクモに似ているということで、「スパイダー」とよばれることもあります。この表現の方がわかりやすいですね。
あるいは、「自動的にリンクを見に行くようプログラムされたロボット」というニュアンスを込めて、「ロボット」とよばれることもあります。
クローラーは自動的に次々と、Webページを巡回していきます。
そして広大なインターネット世界にある膨大な量の情報を取得していくのです。
2-2.クローリングするファイルの種類
Web上にある情報を自動的に取得していくクローラーがたどっていくのは、HTMLのファイルだけではありません。
- JavaScriptで生成されるリンク
- Flashの中にあるリンク
- WordやPowerPointなどのMicrosoft Officeによって作成されたファイル
このような情報も、Googleはクローリングして取得していきます。
2-3.パーシング(解析)
クローラーはリンクをたどることによってページにたどりつきます。
ページにたどりついたクローラーは、「パーシング」を始めます。
新しい言葉が出てきましたね。
パーシングはクローリングの一工程で、「解析」という意味です。
簡単に説明してみましょう。
クローラーはHTMLのコードやPDFファイルなどを読み取り、情報を解析します。解析することで新しいリンクやファイルが発見され、さらにそのリンク先をたどり、情報を解析して新しいリンクを発見し、という行為をひたすらに続けていきます。
クローリングとは、この全過程のことを指します。
一方パーシングは、クローリングの「情報を解析する」という過程のことです。
この情報を解析するプログラムのことを、「パーサー」とよびます。
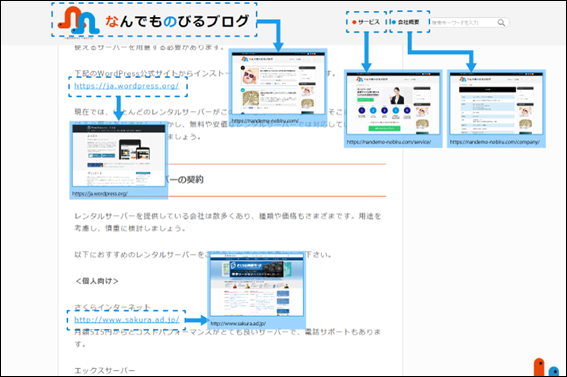
下の画像を見て考えるとわかりやすいでしょう。
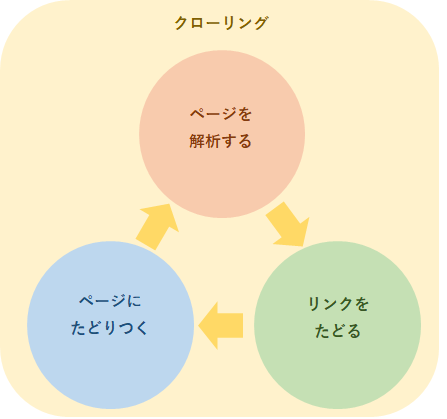
この画像における、「ページを解析する」部分を担当しているプログラムが「パーサー」です。そしてパーサーが行う情報解析のことを、「パーシング」とよびます。
パーサーが解析するのはリンクだけではありません。それ以外の情報も読み込んでいきます。
例を挙げてみていきましょう。
<title>タラバガニ – Wikipedia</title>
パーサーは、上記のようにtitleタグに囲まれている「タラバガニ – Wikipedia」という部分は、そのページのtitle部分であると解析処理を行います。
<img src=”https://upload.wikimedia.org/KingCrab-reverse.JPG” alt=”タラバガニ” />
このように記載されていれば、「https://upload.wikimedia.org/KingCrab-reverse.JPG」は画像で、この画像は「タラバガニ」というテキストと等価であると解析処理をするのです。
例に挙げたtitleタグとalt属性については、それぞれ「SEOの最重要技術「titleタグ」の設定ガイドライン」「軽視されがちだが重要なalt属性の適切な設定とは」を参照してください。
Googleなどの高性能な検索エンジンのパーサーは、JavaScriptの実行結果についても、内容を読み取ってインデクサーに渡せます。常に完全な形でデータを渡せるとは限らないのですが、収集して引き渡すという動作はするということです。
3.クローラーの種類
3-1.Googlebot|Googleのクローラー
Googleのクローラーには、「Googlebot」という名称がついています。
botというのはロボット(robot)の略称です。つまりGoogleのロボットという意味ですね。
3-2.Googlebot以外のクローラー
インターネット上に存在する検索エンジンは、Googleだけではありません。
Google以外の主な検索エンジンとそれぞれのクローラーを列挙してみましょう。
- Bing : BingBot
- Yandex(ロシアの検索エンジン) : YandexBot
- Baidu(中国の検索エンジン): Baiduspider
2016年時点、日本国内におけるSEOでは、Googleだけを考慮すればいいと考えられます。
国内1位のシェアを誇る検索エンジンのYahoo!Japanは、Googleのシステムを利用しているからです。
GoogleとYahoo!で国内におけるほぼすべてのインターネットユーザーを網羅できるうえに、その検索システムが同一であるため、大本であるGoogleについてだけ考えればいいということです。
しかしクローラーについてはGoogle以外も考慮する必要があるため、その理由を「5.クローラーの制御」で後述します。
4.クローリングの確認
検索エンジンから一度存在を知られたURLは、リンクをたどることなくクローリングされます。「一度クローラーが訪れたページには、クローラーが通れる検索エンジン直通の道ができる」と考えるとわかりやすいですね。
では、その道を通ってやってくるクローラーは、どれくらいの頻度でクローリングしていくのでしょうか。
4-1.クローリングの頻度
クローリングは、あらゆるページに対して同じ頻度で行われるわけではありません。
クローリングが頻繁に行われるページには、2つの条件があります。
- 更新頻度が高い
よく更新されるページは頻繁にクローリングされます。
数秒に1回更新されるようなページは1日に何回もクローリングされますが、放置されているページであればクローラーはほとんど来なくなります。 - 重要度が高い
検索エンジンが重要であると判断したページは、クローリングされる頻度があがります。
更新頻度が高くなくても、重要度の高いページであれば、相対的にクローリング頻度はあがる傾向にあります。
4-2.クローリングを確認する方法
「クローリングされているかどうか」は「検索エンジンに認識されているかどうか」を判断する重要な指標です。
自分のWebサイトがクローリングされているかどうか確認してみましょう。
クローリングされているかどうか確認する方法は、主に2つあります。
4-2-1.Google Search Consoleを使う
「Google Search Console」というGoogleが提供しているツールがあります。
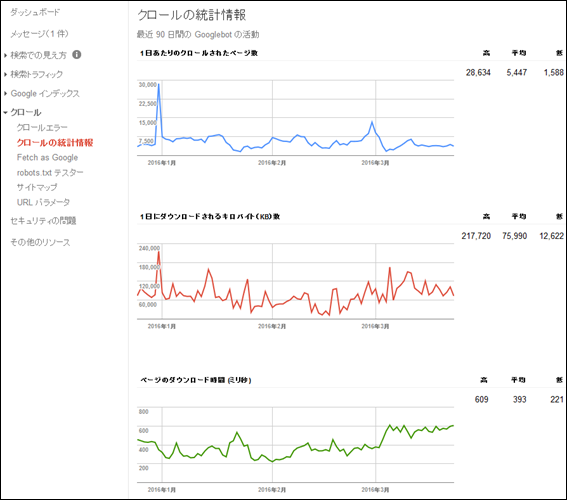
これに自分のWebサイトを登録してログインすると、「クロールの統計情報」というページからクローリングの状況を確認できます。
登録の方法は、「ウェブマスターツールにホームページを登録する方法」に詳しく記されています。参考にするといいでしょう。
下の画面を見れば、1日に何ページクローリングされたか確認することができます。
4-2-2.Webサーバーの生ログを見る
ほとんどのWebサーバーには、アクセスログを保存する機能があります。
アクセスログとは、そのWebサイトにどのようなアクセスがあったかという履歴のことです。閲覧者のIPアドレスやWebページに訪れた時間、使用ブラウザなどの情報を知ることができます。
アクセスログをダウンロードしてテキストエディタなどで開いてみると、詳細なクローリングの履歴がみられます。
アクセスログの保存方法やダウンロード方法はサーバー運用会社ごとに異なるので、契約サーバーの運用会社に問い合わせてみてください。
下の画像が、当ブログの生ログです。

青で囲った部分が閲覧されたページ、オレンジで囲った部分が来訪者を示しています。
ここでは、青が「/2001/」、オレンジが「Googlebot」となっていますね。
アクセスログはドメイン名が省略されるので、「/2001/」は”https://nandemo-nobiru.com/2001/”のことを指します。
つまり、「”https://nandemo-nobiru.com/2001/”というページにGooglebotが来た」ということがわかるのです。
このように、生ログを見ればいつクローリングされたのかを確認できます。
5.クローラーの制御
検索エンジンにWebサイトを認識させるため、あるいは認識させないためには、クローラーの制御が必要です。
自動的にあらゆるリンクをたどって情報を取得していくクローラーですが、その動作はある程度制御できます。
ここでは、クローリングを開始・促進させる、あるいは抑制するための手法を解説していきましょう。
5-1.クローリングを開始させる
新しいWebサイトを作ったとき、検索エンジンはそのWebサイトの存在を知りません。
そしてどこからもリンクされていなければ、検索エンジンはWebサイトの存在に気がつかずに、永遠にクローリングを開始しないかもしれません。
クローリングされなければ、Webサイトが検索結果に表示されることはありません。
そんな事態を防ぐために、Webサイトができたことを検索エンジンに通知する必要があります。
5-1-1.Fetch as Google
通知するもっとも良い方法は、先ほども挙げたGoogle Search Consoleを使うことです。
Google Search ConsoleはSEOにおいて必須ともいえるツールなので、ぜひ登録することをおすすめします。
Google Search Consoleに新しいWebサイトを登録します。その後、Fetch as Googleという機能を使ってクローラーを強制的に呼びよせるのです。
この方法については、下記のページに詳しいので参考にしてください。
1→2という順番で実施してみてください。
この方法を使えば、即時にクローリングが開始されます。
5-1-2.Googleへの巡回申請
Google Search Consoleが使えない場合は、ユーザーによる巡回申請という方法もあります。
Googleにログインした状況で、下記URLにアクセスします。
https://www.google.com/webmasters/tools/submit-url?hl=ja
すると、このような画面が表示されます。
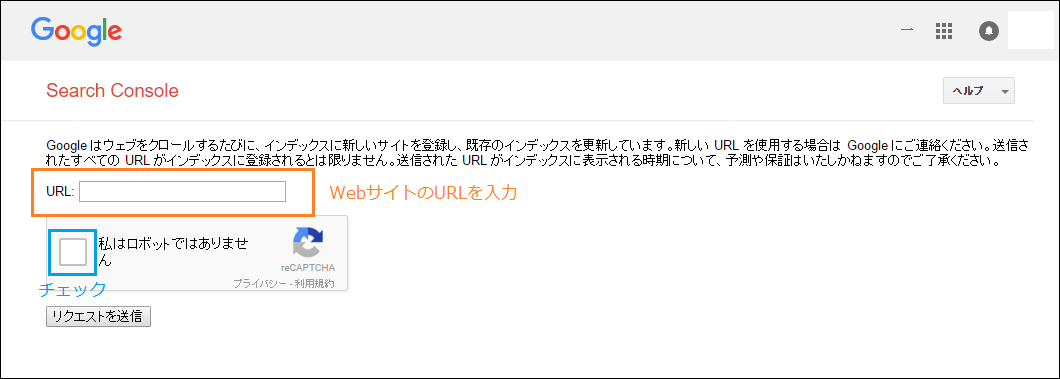
URLの入力欄に入力し、「私はロボットではありません」をチェックし、「リクエストの送信」をクリックします。
これでクローラーを自分のWebサイトに呼びよせることができます。
5-2.クローリングを促進する
Googleは基本的に、「ユーザーの利便性を向上させる」ことを第一に動きます。
ですから、新しいWebページは可能なかぎり早く認識して、検索結果に反映させようとします。新しい情報をタイムリーに反映できれば、鮮度の高い情報をユーザーに提供できて、利便性が高まるからです。
利便性を高めるために、Googleは「クローラーが自動的にリンクをたどる」以外にも、より早くクローリングさせる手段を提供しています。さまざまな手段を状況に応じて使いこなせれば、Webページが検索結果にいち早く表示されるようになります。
有意義なWebページの存在をいちはやく検索エンジンに知らせることができれば、ユーザーの利便性が高まります。
言い換えれば、SEOで優位に立てるということです。
その観点から、クローリングを促進させる方法を知っておくことは非常に重要だといえます。
クローリングを促進させるための代表的な手法として、下表にある5つが挙げられます。
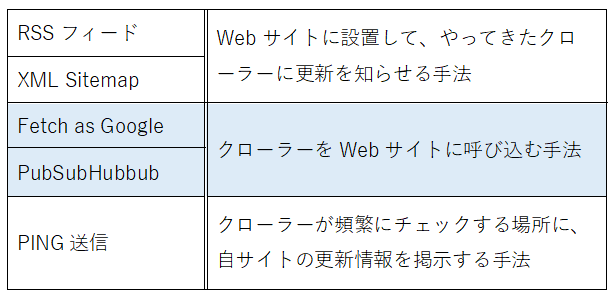
それぞれの手法について、順を追って解説していきましょう。
5-2-1.RSSフィード
RSSフィードは、ページ追加を検索エンジンに伝える良い方法です。
RSSフィードをWebサイトに設置すると、コンピューターにとってわかりやすい形式で、ジの更新情報が一覧になって掲載されます。

こんなアイコンを見たことはありませんか?
これがRSSフィードのアイコンです。RSSフィードを設置しておくと、クローラーはそこから更新情報を読み取ります。
検索エンジンは、リンクをたどっているだけではありません。
RSSフィードもクローリングして情報を取得していくため、Webサイトに設置しておくと、クローラーはリンクをたどらなくても追加ページを把握できます。
WordPressなどのCMS(コンテンツ管理システム)が「SEOに強い」といわれる理由の1つがここにあります。
WordPressを採用すれば、自動的にRSSフィードが設置されるのです。
RSSフィードを自分で作ろうとしたらなかなか大変なので、デフォルト機能として存在することは大きな強みだといえます。
5-2-2.XML Sitemap
XML Sitemapは、その名のとおりサイトマップのようなものです。
ただし、見るのは人間ではありません。検索エンジンが見るための、Webサイト内のページ一覧表のようなものです。
当ブログのXML Sitemapの一部を掲載します。

パッと見ただけではよくわからないかもしれませんが、ここには以下のような情報が記載されています。
- 更新されたページのURL
- いつ更新されたのか
- このURLの更新頻度はどの程度なのか
- クローリングの優先度はどの程度か
これらの情報は、Googleからあまり重要視されていません。
しかしXML Sitemapがあれば、検索エンジンは記載されたURLを把握してクローリングしに行きます。リンクをたどらなくてもページの存在を知ることができるのです。
近年は、こうやって知らせなくても問題ないほどクローラーの性能が向上したため、あまり効果がないともいわれています。
しかし、設置しない理由もないので設置しておくべきです。
WordPressを使えば、「Google XML Sitemaps」などのプラグインを導入することで、簡単に設置できます。
5-2-3.Fetch as Google
クローリングを開始させる方法として紹介したFetch as Googleは、瞬時にクローリングを実行させます。とくに新しいWebサイトを作ったときに有用ですが、促進手段としても役立ちます。
また、いつまで経っても検索結果に表示されないページに対して、「クローリングが正常に行えるようになっているか?」という確認に使うこともできます。
確認方法は、下記ページを参考にすると良いでしょう。
「Fetch as Googleでクローラーに登録する方法」
今回はこの「site Frame Note」というSEOエンジニアが運営するWebサイトから、数多くの記事を引用しています。
詳細にわかりやすく解説されたページが多いので、参考になるはずです。
5-2-4.PubSubHubbub(パブサブハブバブ)
発音すると舌を噛みそうな名前ですね。
これは、ページ追加を検索エンジンにいち早く伝える手法です。
前述のRSSフィードとXML Sitemapは、自分のWebサイト内に設置してクローラーが読み込むことを待つ手法でした。
一方このPubSubHubbubは、ページ追加を能動的に伝えるものです。これを使えば、早ければページを追加して数秒後には検索結果に表示されるようになります。
PubSubHubbubには、積極的に導入すべき理由が1つあります。
それは、Webページが盗作されたときに役立つ可能性があるからです。
Googleは、まったく同一のページが2つあった場合、オリジナルとコピーを判定しようとします。
その判定の重要な基準が、「Googleにいつ登録されたか」なのです。
つまり、先に登録された方がオリジナルであると判断されやすくなります。
もし、自分のWebサイトの内容を第三者にまるごと盗作されてしまった場合、盗作側のWebサイトの方が早くクローリングされていれば、盗作した側がオリジナルだと誤認される可能性があるのです。
そんな事態を防ぐために、PubSubHubbubは使うべきなのです。
PubSubHubbubもWordPressではプラグインで簡単に実装できます。
プラグインの名称は、そのものずばり「PubSubHubbub」です。「PuSHPress」というプラグインも有名で、どちらを使っても大きな違いはありません。
5-2-5.PING送信
さまざまなWebサイトの更新情報が掲載されている、PINGサーバーというサーバーがあります。有名どころとして、以下の2つが挙げられます。
下の画像を見てもらえば、PINGの機能は一目瞭然でしょう。
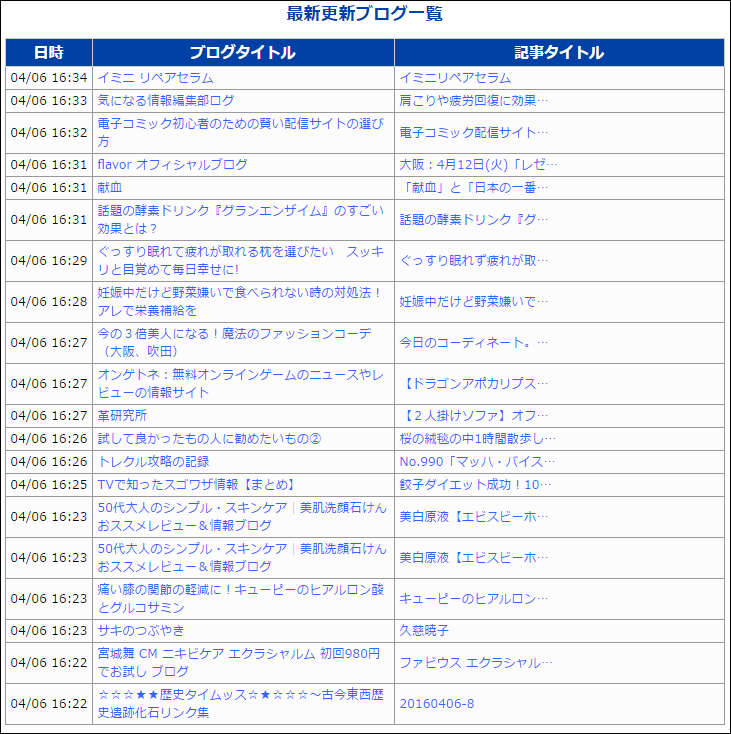
これは、PINGZONEに掲載されているさまざまなブログの更新情報です。
PINGZONEに「自分のブログのページが追加された」という情報を送信すると、上記の更新情報に自動的に掲載されます。
検索エンジンは頻繁にPINGサーバーを巡回しており、表示されている更新情報を取得してクローリングしに行きます。
PINGサーバーに更新情報を送信することで、クローリングを促進できるのです。
最近はクローラーの性能が上がったため、PINGサーバーに送信しなくても、それほどインデックスが遅れることはありません。
しかし、送信したら損であるという理由もないので、送信することをおすすめします。
WordPressでは、PINGサーバーへの送信機能がデフォルトで備わっています。
管理画面の「設定」→「投稿設定」に移動すると、「更新情報サービス」の欄にPINGサーバーのアドレスを入力できます。
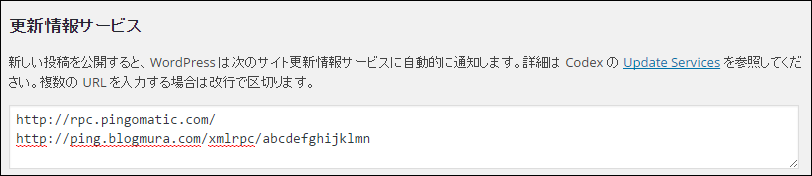
上画像の場合、2行目の「http://ping.blogmura.com/~」というURLは、「ブログ村」というPINGサーバーへPING通知するためのURLです。
ブログ村でアカウントを作成すると、自分用のPING通知URLが取得できます。それを入力するだけでブログ村に更新情報が常に掲載されるようになります。
5-3.クローリングを抑制する
クローリングを促進すべき理由はわかりやすいと思います。
しかし、その反対にクローリングを抑制すべきケースや理由はわかりますか?
クローリングを抑制すべき場合とその手法は、技術論としてのSEOで重要なポイントです。
詳しく解説していきましょう。
5-3-1.抑制するべき場合
クローリングを抑制するべき場合として、以下の3つが挙げられます。
- ページの内容が空であるページへのリンク
- リンク先のページが信頼できない
- Google以外のクローラーを排除したい
それぞれの内容をみていきましょう。
ページの内容が空であるページ
これだけではわかりづらいと思うので、例を挙げてみます。
・日記ブログの未来日など、日記が投稿されていない日へのリンク
この場合、リンクをクリックしても、リンク先のページは空っぽです。
このような「検索結果に表示される価値がないページ」があると、検索エンジンから価値の低いWebサイトだと認識されやすくなります。クローリングしないよう指定することが望ましいでしょう。
・検索結果が0件になるページ
ECサイトや不動産などのサイトで、検索機能で絞り込んだ結果が0件になるページが発生することがあります。
こうしたページをクローリングさせると、検索エンジンに内容の薄いページが大量に登録されます。その結果、上記同様にWebサイト全体の内容が薄いと評価される危険性が高まります。
このような場合、そもそも「情報が存在しないページヘのリンク」自体がおかしいので、リンク自体しないようにしましょう。リンク先のページに情報がないことは、ユーザーにとって苦痛以外の何物でもないからです。
この種のリンクがどうしても避けられない場合には、後述する「nofollow属性」を付けてリンクすることで、クローリングを抑制できます。
リンク先のページが信頼できない
別のページにリンクすると、検索エンジンは「そのWebページがリンク先のページを評価している」とみなします。リンクをするということは、紹介する価値があるページであると宣言していることだからです。
ところが、リンク先のページが検索エンジンの定めるガイドラインに抵触している場合、このリンクが問題となります。
ガイドラインに違反しているページにリンクすることは、検索エンジンから「その行為に加担している」とみなされる可能性があるからです。
このようなページにリンクしなくてはならない場合も、「nofollow属性」を付けてリンクすることで、検索エンジンからの誤解を防ぐことができます。
Google以外のクローラーを排除したい
インターネットには、Google以外にもさまざまな検索エンジンが存在しており、その数だけクローラーも存在しています。
先ほど名前を挙げた「Yandex」と「Baidu」という、2つの検索エンジンを覚えていますか?ロシアと中国の検索エンジンです。
日本語のページであれば、基本的に、これらの検索エンジンに登録される価値はほとんどありません。そして、クローラーが頻繁にアクセスしてくると、Webサーバーに負担がかかります。
つまり、これらのクローラーが巡回してくることは、メリットがなくデメリットが大きいのです。
また、検索エンジンだけではなく、個人や企業が調査用として使用しているクローラーも数多く存在しています。それらのクローラーの中にはrobots.txtの指示に従わないものもあるので、その場合は「.htaccess」で完全にアクセスを禁止することが望ましいです。
現在はあまり問題にならなくなりましたが、かつてBaiduのクローラーは数秒毎にアクセスを繰り返し、Webサーバーに大きな負荷をかけていました。
そしてrobots.txtの指示にも従わないことで、多くのWebマスターは困っていたものです。.htaccessでアクセスできないようにする自衛策を取らなければならない時期もありました。
5-3-2.抑制する方法
それでは、クローリングを抑制したいときはどんな手段をとればいいのでしょうか。
クローラーの動作を、先ほどよりも細かく追ってみましょう。
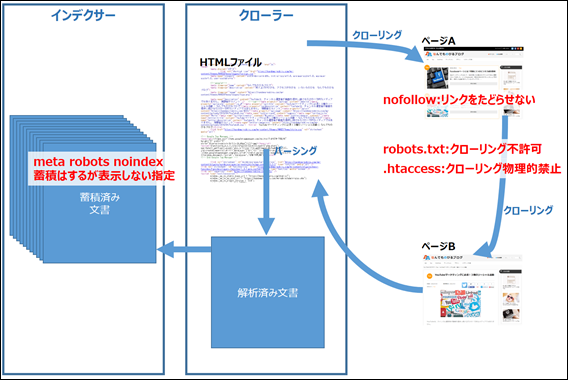
ページAと、そこからリンクでつながれたページBがあったとします。
この場合、クローラーはページAをパーシングしてリンクを発見し、ページBへ移動します。そしてページBもパーシングして、それぞれのページの情報をインデクサーに引き渡します。
それを踏まえて、「ページAは検索結果に表示させたいが、ページAからリンクされているページBは表示させたくない」というケースを想定して、抑制方法を解説していきます。
以下の5つが、クローリングを抑制する代表的な手法です。
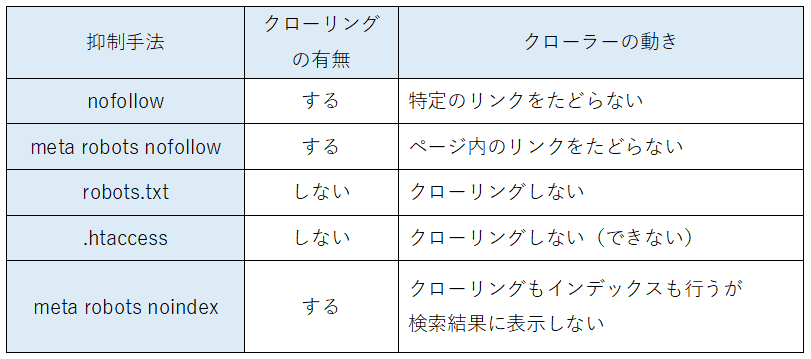
それぞれの手法について、順を追って解説していきましょう。
nofollow|特定のリンクをたどらないようにする
ページAからページBへのリンクにnofollow属性をつけることで、クローラーがリンクをたどらないように制御できます。
nofollow属性は、特定のリンク先をクローラーが巡回しないように指定する方法です。
ページAの中にある、ページBへのリンクにnofollow属性を下記のようにして付与します。
<a href=”http://www.example.com/page-b/” rel=”nofollow”>
このように記述すると、クローラーはページBへのリンクをたどらなくなります。
とはいえ、「クローラーがページBに絶対たどつかない」という保証はありません。たとえば、ページCからのページBへのリンクがあって、そこにnofollowが付与されていなければ、クローラーはページBへたどりつきます。
meta robots nofollow|ページ全体のリンクをたどらないようにする
ページ内すべてのリンクに対して、クローラーが巡回しないように指定する方法です。
ページAのheadタグ内にmeta robots nofollowタグを記述することで実行できます。
<meta name=”robots” content=”nofollow”>
上のタグをhead内に記述すると、クローラーはページAにあるすべてのリンクをたどらなくなります。しかしnofollow属性と同様の理由によって、ページBにクローラーがたどりつく可能性があります。
robots.txt|クローリングの不許可
robots.txtというファイルをドメインの直下に設置する方法です。
クローラーは、Webサイトをクローリングする前にこのrobots.txtを読み取り、この中の指示を受け取ります。robots.txtに「このページをクローリングしてはいけない」などの指示を書き込むことで、クローラーの動きを制御できます。
GoogleやBingのクローラーは、絶対にこの指示に従います。

上のように記述したテキストを作成して、「robots.txt」というファイル名で保存し、ドメインのルート直下に設置すればできあがりです。
この例であれば、「Googlebotは/page-b/というファイルをクローリングしてはいけない」という意味になり、Googlebot(Googleのクローラー)はこれに従います。
.htaccess|クローリングを禁止する
.htaccessというファイルを、特定のディレクトリに設置する方法です。
このファイルはWebサーバーの動作を指示するものです。
Googlebotが特定のディレクトリにあるファイルをクローリングしようとしたとき、WebサーバーがそのファイルをGooglebotに見せないようにできます。
.htaccessファイルをドメインルート直下に設置すると、Webサーバーは指示されたように動作するのです。
記述方法や使い方は難しく、設定を間違えるとWebサイトにアクセスできなくなる可能性もあります。
そのため、あえてこのページでは説明しません。
meta robots noindexとmeta robots nofollow|検索結果に表示させない
meta robots noindexタグとmeta robots nofollowタグを、ページのhead内に記述する方法です。
これを記述してもパーシングに影響はないので、クローラーはページ内にあるリンクをたどります。
しかし、検索結果にはWebページが表示されなくなります。
ページBのheadタグ内にmeta robots noindexタグを下記のように記述します。
<meta name=”robots” content=”noindex”>
ページAのhead内に上記タグを挿入すると、ページBは検索結果に表示されなくなります。クローリングはされるしインデックスもされますが、検索結果には反映されなくなるのです。
通常、meta robots noindexとmeta robots nofollowは一緒に記述します。
<meta name=”robots” content=”noindex,nofollow”/>
noindexでかつnofollow指定する場合には、上記のように記述します。
6.クローラビリティを高める
最後に、クローラビリティを高める方法を紹介します。
クローラビリティとは、「クローリングのしやすさ」のことです。
クローラビリティを高めることは、5章で紹介したクローラーの制御方法よりも、SEOの技術としてずっと重要なポイントです。
なぜなら、クローリングしやすいWebサイトとは、「検索エンジンから見て理解しやすいWebサイトである」といえるからです。
そして、理解しやすいページは検索エンジンからの評価が上がりやすいのです。
極端な例ですが、トップページからどのようにしても辿りつけないページがあったとします。
このようなページは、XML Sitemapなどがあればクローリングされるでしょう。しかし、クローリングされても検索エンジンの評価は上がらないことが多いです。
どこからもリンクで辿れないページとは、Webサイト内における位置付けが検索エンジンには理解できないのです。
クローリングしづらいWebサイトとは、ほぼイコールでユーザーにとって利便性が低いサイトであるともいえます。
Googleはユーザーの利便性を重視するので、ユーザーにとって動きづらいと判断されたサイトは評価が下がります。そして判断する指標の1つとして、クローラビリティがあるのです。
それでは、クローラビリティを高める方法を紹介していきます。
6-1.リンクのないページを排除する
リンクがまったく存在しないページは、クローラビリティを低下させる要因の1つです。
WordPressなどのCMSを導入しているのであれば、基本的にこのようなページは発生しません。
しかし、「CMSの自作」「手打ちのHTMLでのWebサイト作成」などケースでは、このような問題がたびたび発生します。
HTMLでWebサイトを作っている場合、更新するときの不注意でこういった問題がよく起こります。
WordPressがとりわけSEO的に優れているわけではないのですが、この問題が発生しないだけでも、SEO的な観点からは大きな価値があります。
詳細:WordPressのSEOに強いポイント・弱いポイント
6-2.リンクの数を適正に抑える
1つのページにリンクが1,000箇所もあるといった場合に、クローラーはすべてのリンクをたどってくれるとはかぎりません。
これはあくまで目安なのですが、1つのページでのリンクは100箇所程度に抑えておきましょう。
もしそれよりもリンクが多くなってしまうのであれば、別のルートでもたどりつけるようにしておくべきです。
6-3.トップページからの必要クリック数を抑える
できることなら、どのページに対してもトップページから3クリック以内で到達できることが理想です。
トップページから該当ページまでのクリック数が多いと、クローラーは何度もサイト内のリンクをたどり続けなければなりません。
これはクローラビリティを低下させる要素の1つです。
もちろん、ユーザーにとって利便性が低いページであるともいえます。
6-4.トップページから主要ページへ直接リンクする
ユーザーにとって必要なページは、トップページから直接リンクするようにしましょう。
あるいは、グローバルナビゲーション(全ページに共通のリンク)でリンクすることが望ましいです。
6-5.ページ送りを少なくする
「トップページからの必要クリック数を抑える」ことと関係しますが、ページ送りを何十回も行わないと辿りつけないようなページ送りは、クローリングに非常に手間がかかるのです。
延々とページ送りをしないと辿りつけないページは、クローリングされないことがあります。
そのため、下記のような配慮をすることが望ましいといえます。
- 1ページ当たりの表示件数を多くする。
- 1ページずつページ送りしなくても、ずっと先のページに一気にたどりつけるページナビゲーションにする。
【例】
[1] [2] [3] [4] [10] [20]
このようなページ送りにすると、ページ送りの回数を減らすことができます。
6-6.Javascriptでのリンクを避ける
GoogleはJavascriptによって生成されたリンクを辿ることができますが、確実なものではありません。
重要なページヘのリンクはJavascriptだけではなく、HTMLによるリンクも用意して確実にクローリングできるようにしましょう。
6-7.複雑なURLを避ける
2010年頃まではURLは短く単純な方がクローリングされやすかったのですが、クローラーの性能の上がった2016年現在は、それほど変わりありません。
とはいえ、あまりにも複雑なURLはクローリングの妨げになるので避けたほうが無難です。
7.最後に|クロールバジェットを気にする必要はない
近年、クロールバジェット (CrawlBudget)という言葉がにわかにSEO界隈を騒がせています。
個々のWebサイトごとにクロールバジェットというものが決まっているというのです。
バジェットとは「予算」という意味です。
GoogleはWebサイトの評価に応じて、クロールする量を決めているというのです。
評価が高いWebサイトはクロールバジェットが多く、そうでないページは少ないということです。
ですから、「nofollowを使う」「ページ数を減らす」といった対応を行わないと、クロールバジェットの制限に引っかかって、全ページクローリングされなくなるといわれているのです。
これは確かに嘘ではありません。
しかし一般のWebマスターにとっては、まったくなんの関係もない話です。
規模の小さいWebサイトのクロールバジェットは確かに少なくなりますが、尽きるほど少なくなるケースはないといってもいいでしょう。
数億ページ以上もあるサイトであれば考慮する必要がありますが、そんなWebサイトを運営している人はごくまれだと思います。
一般的な、数百数千、あるいは数万ページ程度のWebサイトであれば、クロールバジェットを気にする必要はありません。
検索結果に表示されないときにクロールバジェットを気にする人がいますが、たいていの場合、クローラビリティが悪いためにインデックスされていないのです。
クロールバジェットなんていう用語をきいたがために、
「nofollowを使わなくちゃ!」
と思う方がいるかもしれません。
しかし、こんな言葉は忘れてください。どうでもいいことです。
nofollowはクローリングの阻害要因であり、わざわざ自分のWebサイト内のページへのリンクにnofollowをする必要は、基本的にはないのです。